Manualne testowanie AI: dlaczego potrzebujemy nowego podejścia?



Manualne testowanie jednego modelu AI może kosztować firmę nawet 70 000 euro rocznie. Taki koszt wynika z nieefektywnego podejścia, w którym zespoły analityków próbują nadążyć za zmiennością i złożonością algorytmów.
W odpowiedzi na te rosnące wyzwania powstały zautomatyzowane platformy do AI Governance, takie jak Auditor. Naturalnie, możemy (a nawet powinniśmy) zapytać: czy na obecnym etapie rozwoju w pełni zastępują one manualne testy? W tym wpisie blogowym odpowiemy na to pytanie, zestawiając koszty i ryzyka obu strategii.
Kluczowe wnioski
- Wysokie koszty manualnej pracy: Manualne testowanie jednego modelu AI to roczny koszt sięgający nawet 70 000 euro, co czyni ten proces nieskalowalnym i nieefektywnym w większej skali.
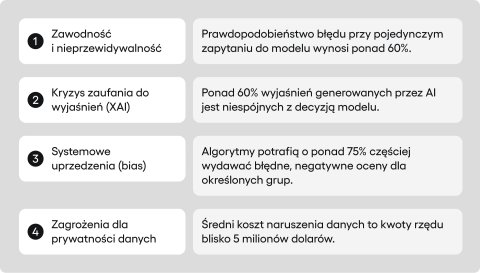
- Wbudowana zawodność AI: Systemy AI są z natury zawodne – prawdopodobieństwo wystąpienia błędu (np. halucynacji, uprzedzeń) przy jednym zapytaniu wynosi ponad 62%.
- Ryzyko systemowych uprzedzeń: Modele AI utrwalają i wzmacniają ludzkie uprzedzenia. Jak wskazują analizy Congressional Black Caucus Foundation, algorytm systemu COMPAS o 77% częściej błędnie i negatywnie oceniał czarnoskórych oskarżonych.
- Kryzys zaufania do wyjaśnień: Wyjaśnienia generowane przez AI (XAI) często są niewiarygodne. Badania opublikowane na platformie arXiv wskazują, że ponad 62% z nich może być niespójnych z faktycznym procesem decyzyjnym modelu, co tworzy fałszywe poczucie bezpieczeństwa.
- Mierzalne oszczędności z automatyzacji: Zautomatyzowane platformy do nadzoru, takie jak Auditor, mogą zredukować koszty testów i audytu o 57%, a koszty raportowania aż o 81%.
- Luka w zarządzaniu ryzykiem: Według portalu Artificial Intelligence News, zaledwie 5% firm posiada dojrzałe systemy zarządzania AI, co tworzy ogromną lukę w zarządzaniu ryzykiem, którą gotowe platformy mogą szybko wypełnić.
Fundamenty problemu: dlaczego manualne testowanie AI zawodzi?
Zanim przejdziemy do rozwiązań, musimy dogłębnie zrozumieć naturę problemów, z jakimi mierzą się zespoły deweloperskie i biznes. Jak podaje portal Exploding Topics, rynek AI ma osiągnąć wartość 391 miliardów dolarów, a według testRigor, aż 99% firm z listy Fortune 500 już wdraża tę technologię. Ten dynamiczny rozwój zderza się jednak z rosnącą presją regulacyjną i świadomością ryzyka. Tradycyjne metody zapewniania jakości okazują się dramatycznie niewystarczające.
Bariera kosztów i skalowalności w testach manualnych
Manualne testowanie AI to proces, w którym człowiek – tester – ręcznie weryfikuje działanie systemu, szukając błędów czy nieścisłości. W pewnych, bardzo specyficznych obszarach, ludzka intuicja i zdolność do oceny subiektywnych aspektów, takich jak niuanse etyczne czy kontekst kulturowy, wciąż wydają się niezastąpione.
Przykładowo, testy eksploracyjne, które charakteryzują się większą spontanicznością w porównaniu do regresji, pozwalają nam odkrywać nieoczywiste zachowania modeli, których nie przewidziano w specyfikacji. Jednakże, w dobie AI, poleganie na testowaniu manualnym jako głównym mechanizmie kontroli jakości jest nie tylko nieefektywne, ale wręcz niebezpieczne. Jego rola staje się niewystarczająca, szczególnie w kontekście rosnącej potrzeby wdrażania zaawansowanych i zautomatyzowanych mechanizmów kontroli.
Skala problemu staje się jasna, gdy spojrzymy na twarde dane finansowe. Średni roczny koszt obsługi testów jednego modelu AI w bankowości może sięgać nawet 70 000 euro. Skąd bierze się ta kwota? To głównie koszty wysoko wykwalifikowanych specjalistów, którzy muszą poświęcać setki godzin na żmudne, powtarzalne zadania. Kiedy organizacja planuje wdrożenie kilku lub kilkunastu modeli, koszty te potrafią rosnąć wykładniczo.
Manualne testowanie AI: niespójność i ryzyko błędu ludzkiego
Konsekwencje biznesowe tych ograniczeń wykraczają daleko poza sam budżet. Pierwszym i najbardziej oczywistym problemem jest niska skalowalność. Proces manualny z natury jest powolny i zasobochłonny. Każdy nowy sprint deweloperski, każda zmiana w modelu czy danych treningowych wymaga ponownego uruchomienia, czasochłonnego cyklu testów regresji. W świecie zdominowanym przez podejście, w którym szybkość wdrożeń jest kluczowa, manualne testy stają się wąskim gardłem. Dla organizacji, które chcą dynamicznie rozwijać swoje portfolio produktów opartych na AI, jest to fizyczna bariera niemal niemożliwa do przeskoczenia.
Drugim, równie istotnym ryzykiem, jest niespójność. Manualne testy są podatne na błąd ludzki. Zmęczenie, rutyna, subiektywna interpretacja wymagań – wszystko to sprawia, że dwóch testerów, badając dokładnie ten sam scenariusz, może dojść do zupełnie różnych wniosków.
Problem ten nabiera szczególnego znaczenia, jeśli mówimy o audytach zgodności z regulacjami takimi jak np. AI Act. Dlaczego? Powód jest prosty. Jeśli model AI, który został błędnie uznany za zgodny, zostanie wprowadzony na rynek, firma jest narażona na poważne sankcje finansowe. Mówimy tu o karach, które mogą sięgać milionów euro lub procentu od globalnego obrotu firmy.
Z tego powodu audyty AI wymagają szczególnej konsekwencji, wręcz maszynowej powtarzalności wyników i precyzyjnie udokumentowanej metodologii. Z kolei procesy manualne, z ich wrodzoną zmiennością, po prostu nie są w stanie dostarczyć tego poziomu pewności dla przedsiębiorstw.
Manualne testowanie AI wykazuje trudności w wykrywaniu wzorców systemowych
Najgłośniejsze i najbardziej kosztowne porażki systemów AI – takie jak stronniczość w systemach rekrutacyjnych czy sądowniczych – nie wynikały z pojedynczych, łatwych do wychwycenia błędów. Były one rezultatem systemowych wzorców, których manualne procesy nadzoru nie były w stanie wykryć. Człowiek, analizując kilkadziesiąt czy nawet kilkaset odpowiedzi modelu, nie jest w stanie dostrzec subtelnych, statystycznych odchyleń rozłożonych na milionach punktów danych. To właśnie fundamentalne ograniczenia ludzkiej percepcji w analizie na wielką skalę są głównym źródłem tego ryzyka.
Warto również zauważyć, że modele AI wdrażane w środowiskach produkcyjnych, szczególnie w sektorach o wysokim ryzyku, jak finanse czy medycyna, i tak wymagają wbudowanych mechanizmów kontroli, tzw. guardrails. Są to automatyczne bariery ochronne, które sprawdzają odpowiedzi modelu w czasie rzeczywistym, zanim trafią one do użytkownika końcowego, blokując np. treści niebezpieczne czy niezgodne z polityką firmy. I tu dochodzimy do wniosku, że skoro organizacje i tak muszą inwestować w rozwój tych mechanizmów dla środowiska produkcyjnego, logicznym krokiem jest wykorzystanie podobnych mechanizmów do automatycznego testowania modeli AI.
Główne wektory ryzyka w systemach sztucznej inteligencji
Niedeterministyczna natura AI jako źródło niepewności
Systemy sztucznej inteligencji, w przeciwieństwie do tradycyjnego oprogramowania, działają w sposób niedeterministyczny. Oznacza to, że to samo zapytanie (prompt) skierowane do modelu dwukrotnie, może wygenerować dwie różne, choć często semantycznie podobne, odpowiedzi. Ta fundamentalna cecha, wynikająca ze złożoności sieci neuronowych i probabilistycznej natury ich działania, jest źródłem ogromnego potencjału AI, stanowiąc jednocześnie jedno z największych wyzwań testowych.
Mimo że dostawcy modeli językowych chwalą się wysoką skutecznością w testach syntetycznych, ich wydajność w realnych zastosowaniach jest często ograniczana przez złożone, wzajemnie powiązane wady techniczne i etyczne. Dlatego ocena AI wykracza daleko poza proste stwierdzenie, czy system „działa”, czy „nie działa”.
Pomimo zastosowania nowoczesnych technik, takich jak fine-tuning i Retrieval-Augmented Generation (RAG), średnie prawdopodobieństwo wystąpienia co najmniej jednego z 11 błędów przy pojedynczym żądaniu w przypadku modelu GPT-4 wynosi aż 62,46%. Oznacza to, że nawet dobrze skonfigurowane systemy AI narażone są na halucynacje, uprzedzenia czy podatność na wstrzykiwanie promptów.
Kryzys wierności i problem „czarnej skrzynki”
Złożone modele AI, takie jak głębokie sieci neuronowe, często porównywane są do “czarnych skrzynek”. Termin ten odnosi się do sytuacji, w której możemy jedynie obserwować dane wejściowe (wejścia) i otrzymane wyniki (wyjścia). Z kolei wnioskowanie i podejmowanie decyzji danego modelu nie są dla nas zrozumiałe.
Aby jednak poznać procesy zachodzące wewnątrz “czarnej skrzynki”, narodziła się cała dziedzina Explainable AI (XAI). Dostarcza ona technik i narzędzi pozwalających nieco lepiej poznać sposób “myślenia” modeli AI.
Jednakże, rozwiązując jeden problem, stworzyliśmy kolejny, być może jeszcze głębszy: kryzys wierności (faithfulness). Problem wierności polega na tym, że wyjaśnienie wygenerowane przez system XAI niekoniecznie jest prawdziwym odzwierciedleniem faktycznego procesu decyzyjnego modelu.
Innymi słowy, model może przedstawić logicznie brzmiące uzasadnienie swojej odpowiedzi, które w rzeczywistości nie ma nic wspólnego z tym, jak ta odpowiedź powstała.
Sytuacja nabiera krytycznego znaczenia w sektorach regulowanych, jak np. finanse. Dlaczego? Firmy bowiem są wręcz zobowiązane udowodnić regulatorowi, dlaczego np. odrzuciły wniosek kredytowy – w tym przypadku brak wiarygodnego wyjaśnienia może prowadzić do finansowych konsekwencji.
Co więcej, może to prowadzić do sytuacji, w której zespoły podejmują kluczowe decyzje biznesowe na podstawie fałszywych lub mylących przesłanek, wierząc, że rozumieją działanie modelu, podczas gdy w rzeczywistości opierają się na iluzji.
Skala tego zjawiska daje do myślenia. Badania opublikowane w Proceedings of Machine Learning Research pokazują, że bez odpowiedniej konfiguracji, metryki spójności dla popularnych narzędzi XAI mogą być skrajnie niskie (nawet 0.0), a jak wskazują inne analizy w serwisie arXiv, ponad 62% wyjaśnień generowanych przez LLM jest niespójnych z decyzją modelu.
Systemowe uprzedzenia (bias) i ich konsekwencje prawne oraz wizerunkowe
Ryzyko uprzedzeń (bias) jest uznawane za jeden z najbardziej społecznie szkodliwych problemów związanych z AI. Modele sztucznej inteligencji uczą się na podstawie danych, które dostarczamy im w trakcie treningu. Jeśli te dane odzwierciedlają istniejące w społeczeństwie uprzedzenia – rasowe, płciowe, wiekowe czy inne – model je wzmocni, i to na masową skalę.
System AI może w sposób niezamierzony potęgować nierówne traktowanie względem różnych grup społecznych. Przykładem może być system rekrutacyjny, który faworyzuje aplikacje mężczyzn ze względu na fakt, że w przeszłości na danym stanowisku pracowało mniej kobiet. Takie działanie naraża organizację na potrójne ryzyko: prawne (naruszenie przepisów o niedyskryminacji, np. w HR lub finansach), wizerunkowe (publiczny skandal i utrata zaufania klientów) oraz biznesowe (wykluczenie całych segmentów rynku).
Skala problemu nie jest teoretyczna. Jak czytamy w raporcie Congressional Black Caucus Foundation, system COMPAS o 77% częściej negatywnie oceniał ryzyko w przypadku czarnoskórych oskarżonych. Z kolei badania przeprowadzone przez USC Viterbi School of Engineering wykazały, że od 3,4% do 38,6% tzw. “faktów” w bazach wiedzy AI posiada znamiona stronniczości.
Nowe zagrożenia dla prywatności danych w erze AI
Masowe wykorzystanie danych do trenowania modeli sztucznej inteligencji otworzyło zupełnie nowe wektory ataków, które stanowią fundamentalne zagrożenie dla prywatności. Jednym z najbardziej znanych jest atak typu Membership Inference. Polega on na tym, że osoba atakująca, poprzez serię sprytnie skonstruowanych zapytań do modelu, jest w stanie z wysokim prawdopodobieństwem stwierdzić, czy dane konkretnej osoby (np. jej historia medyczna czy finansowa) zostały użyte w zbiorze treningowym. Nawet jeśli model nie ujawnia tych danych bezpośrednio, sama informacja o ich wykorzystaniu stanowi poważne naruszenie prywatności.
Ryzyko to ma bardzo konkretny wymiar finansowy i wizerunkowy. Globalny średni koszt naruszenia danych w 2024 roku wyniósł 4,88 miliona dolarów, a jak podaje Termly, 57% konsumentów obawia się o swoją prywatność w kontekście AI.
W obliczu tych zagrożeń, jedynym skutecznym podejściem jest filozofia “privacy-by-design”, czyli projektowanie z myślą o prywatności od samego początku. Ochrona danych nie może być dodatkiem czy funkcją, którą próbuje się “dokleić” do gotowego systemu. Musi być integralną częścią architektury, wbudowaną w każdy jej element – od sposobu pozyskiwania danych treningowych i ich anonimizacji, przez zabezpieczenia samego modelu, aż po kontrolę dostępu i mechanizmy zapobiegające wyciekom informacji.
Zautomatyzowany nadzór jako odpowiedź na wyzwania
Wyżej wymienione problemy nieuchronnie prowadzą nas do wniosku, że manualne testowanie AI to ślepa uliczka. Z kolei bezpieczne skalowanie wymaga obecności systemów do zarządzania i nadzoru, które automatyzują procesy kontrolne.
Czym jest Auditor?
Auditor to zintegrowana platforma do AI Governance, czyli kompleksowego zarządzania ładem w obszarze sztucznej inteligencji. Jej celem jest zautomatyzowanie wszystkich kluczowych procesów związanych z testowaniem, ciągłym nadzorem, optymalizacją (trenowaniem), raportowaniem oraz audytem systemów opartych na AI.
Auditor zawiera wszystkie narzędzia niezbędne do zapewnienia, że systemy AI w organizacji są bezpieczne, rzetelne, etyczne i w pełni zgodne z obowiązującymi regulacjami oraz wewnętrznymi politykami jakości. W skrócie: zamiast budować od zera i integrować ze sobą dziesiątki rozproszonych narzędzi, firma otrzymuje gotowe, kompleksowe rozwiązanie.
W jaki sposób Auditor odpowiada na kluczowe ryzyka?
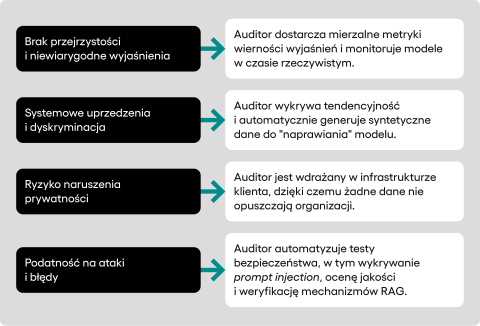
- Odpowiedź na koszty i skalowalność: Auditor bezpośrednio uderza w źródło problemu, jakim jest manualna, powtarzalna praca. Platforma automatyzuje szeroki zakres procesów testowych, w tym testy bezpieczeństwa (np. wykrywanie podatności na prompt injection), ocenę tendencyjności (bias), weryfikację jakości merytorycznej odpowiedzi oraz ocenę wydajności i poprawności działania mechanizmów RAG. To bezpośrednio adresuje problem gigantycznych kosztów i zdejmuje z zespołów deweloperskich ciężar powolnych, manualnych testów, przyspieszając cykl wdrożeniowy.
- Odpowiedź na problem przejrzystości i wierności: W przeciwieństwie do systemów, które same działają jak “czarna skrzynka”, Auditor został zbudowany na fundamencie przejrzystości. Platforma dostarcza twarde, mierzalne metryki dotyczące każdego aspektu działania modelu, w tym wierności jego wyjaśnień. Automatycznie i w sposób ciągły monitoruje modele produkcyjne, wykrywa incydenty i raportuje błędy w czasie rzeczywistym. Co kluczowe, przypadki brzegowe (tzw. edge case’y), czyli rzadkie, nietypowe lub ryzykowne sytuacje, w których system może łatwo popełnić błąd, podlegają ludzkiemu nadzorowi. System automatycznie flaguje takie niejednoznaczne odpowiedzi i przedstawia je ekspertowi do oceny.
- Odpowiedź na problem uprzedzeń: Auditor podchodzi do problemu uprzedzeń w sposób systemowy, wspierając jednorazową ocenę tendencyjności i pozwalając na zarządzanie politykami dotyczącymi przypadków użycia (use case policy). Organizacja może zdefiniować własne, precyzyjne zasady dotyczące np. języka inkluzywnego czy niedyskryminacji, a Auditor będzie automatycznie monitorował ich przestrzeganie. Kluczową i unikalną funkcją jest jednak automatyczne generowanie syntetycznych datasetów do fine-tuningu. Gdy platforma wykryje systematyczną stronniczość w modelu, potrafi stworzyć dedykowany zestaw danych korygujących, służący do “naprawienia” modelu. Tworzy to potężną, zamkniętą pętlę zwrotną (feedback loop), która pozwala na ciągłe doskonalenie modeli w oparciu o wykryte błędy.
- Odpowiedź na problem prywatności danych: W kwestii bezpieczeństwa danych Auditor przyjmuje bezkompromisowe podejście. Platforma jest zaprojektowana do wdrożenia, które integruje się bezpośrednio z infrastrukturą klienta (on-premise lub w prywatnej chmurze). Oznacza to, że żadne dane – ani treningowe, ani prompt-y, ani odpowiedzi modelu – nie wychodzą “na zewnątrz”, do dostawców trzecich.
Strategiczne korzyści z automatyzacji nadzoru nad AI
Mierzalne oszczędności finansowe jako bezpośredni zwrot z inwestycji
Wdrożenie Auditora pozwala osiągnąć konkretne, prognozowane oszczędności, które można wpisać bezpośrednio do budżetu. Szacunki oparte na dotychczasowych wdrożeniach wskazują na redukcję kosztów na poziomie:
- -57% w obszarze testów, audytu i bieżącego nadzoru nad modelami.
- -81% w obszarze tworzenia raportów na potrzeby zgodności (compliance) i wewnętrznego zarządu.
Wypełnienie „luki w zarządzaniu AI”
Jak podaje portal Artificial Intelligence News, zaledwie 5% firm posiada dojrzałe, wdrożone frameworki do zarządzania sztuczną inteligencją. Reszta albo działa w sposób reaktywny, gasząc pożary, albo dopiero zaczyna prace nad stworzeniem własnych, wewnętrznych procesów, co jest zadaniem czasochłonnym i kosztownym. Auditor oferuje gotowe, kompleksowe rozwiązanie “z pudełka”, które pozwala nadrobić tę zaległość i w ciągu kilku miesięcy osiągnąć poziom dojrzałości, na który inni będą pracować latami.
Manuale testowanie AI vs Auditor: podsumowanie
Manualne testowanie AI jest ślepą uliczką – jest zbyt drogie, za wolne i niezdolne do wykrycia systemowych ryzyk, takich jak ukryte uprzedzenia czy niewiarygodne wyjaśnienia generowane przez modele. W dobie masowego wdrażania sztucznej inteligencji, takie podejście generuje tylko ogromne koszty, stwarzając niebezpieczną iluzję kontroli.
Rozwiązaniem jest automatyzacja nadzoru. Platformy takie jak Auditor przekształcają zarządzanie AI z reaktywnego gaszenia pożarów w ustrukturyzowany proces oparty na twardych danych. Dla firmy oznacza to potrójną korzyść: drastyczną redukcję kosztów utrzymania zespołów QA, krytyczne zarządzanie ryzykiem w obliczu regulacji takich jak AI Act oraz – dzięki integracji z CI/CD – możliwość znacznie szybszego i bezpieczniejszego wdrażania innowacji.
Artykuły na tym blogu tworzy zespół ekspertów specjalizujących się w AI, rozwoju aplikacji webowych i mobilnych, doradztwie technicznym oraz projektowaniu produktów cyfrowych. Naszym celem nie jest marketing, a dostarczanie wartościowych materiałów edukacyjnych.


