The manual AI testing trap: why we need a new approach



Manual AI Testing of a single model by hand can cost a company as much as €70,000 a year. This cost comes from an old-fashioned way of working, where teams of analysts try to keep up with how fast and complicated these systems are changing.
In response to these growing problems, automated platforms for AI governance, like Auditor, have been created. Of course, we can and should ask: at this stage, do they completely replace manual AI testing? In this blog post, we will answer that question by comparing the costs and risks of both strategies.
Key findings
- High cost of manual work: Manually testing one AI model can cost up to €70,000 annually. This makes the process impossible to scale up and not very effective.
- Built-in unreliability: AI systems are naturally prone to making mistakes. There is a greater than 62% chance of an error in a single response.
- Risk of systemic bias: AI models can copy and even amplify human biases. Analyses by the Congressional Black Caucus Foundation showed the COMPAS system algorithm was 77% more likely to wrongly assess risk for black defendants.
- A crisis of trust in explanations: The explanations that AI gives for its decisions are often not believable. Research published on the arXiv platform shows that over 62% of them might not match how the model actually made its decision.
- Real savings from automation: Automated platforms like Auditor can cut the costs of testing and auditing by 57%. They can also reduce the cost of creating reports by as much as 81%.
- A gap in risk management: According to the Artificial Intelligence News portal, only 5% of companies have proper systems in place for managing AI. This leaves a huge gap in risk management that ready-made platforms can quickly fill.
The root of the problem: why traditional AI testing fails
Before we look at solutions, we need to get to grips with the problems that development and business teams are facing. The old ways of checking quality that worked for normal software are proving to be completely inadequate for AI. This is because AI doesn’t always act in a predictable way.
According to the Exploding Topics portal, the AI market is set to reach a value of $391 billion. At the same time, testRigor reports that 99% of Fortune 500 companies are already using this technology. This fast growth is meeting with increasing pressure from regulators and a greater awareness of the risks involved.
The barrier of cost and scalability in manual AI testing
Manual AI testing is a process where a person, a tester, checks how a system works by hand, looking for mistakes or things that are not quite right. In some very specific areas, human intuition still seems to be the best tool. For example, a person is better at judging things like ethical details or cultural context.
Exploratory tests are a good example of this. These tests are more spontaneous than standard checks and let us find unexpected model behaviours that were not planned for. In the age of AI, however, relying on manual testing as the main way to control quality is not just inefficient, it’s dangerous.
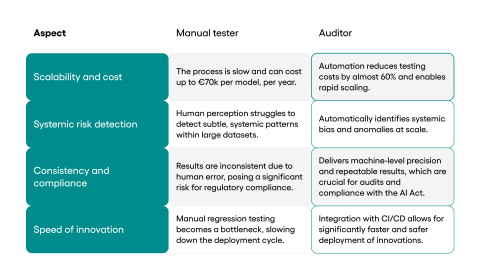
The scale of the problem becomes clear when we look at the hard financial data. The average annual cost of testing a single AI model in the banking sector can be as high as €70,000. This large sum comes mainly from the cost of highly skilled specialists who have to spend hundreds of hours on slow, repetitive tasks.
Inconsistency and the risk of human error
The business consequences of these limits go far beyond the budget. The most obvious problem is the difficulty in scaling up. The manual process is naturally slow and needs a lot of resources.
Every new development sprint, every change to the model or training data, requires another time-consuming round of tests. In a world where speed is everything, manual tests become a bottleneck. For organisations that want to grow their AI-based product range quickly, this is a physical barrier that’s almost impossible to get past.
Another equally big risk is inconsistency. Manual tests are open to human error. Tiredness, routine, and personal interpretation of what’s required all mean that two testers looking at the exact same scenario can come to very different conclusions.
This becomes a major issue when it comes to compliance audits for regulations like the AI Act. Audits need to be completely consistent and repeatable, with a well-documented method. Manual processes, with their natural variability, simply cannot offer this level of certainty.
The hidden risk: failing to spot systemic patterns
The biggest failures of AI systems, like biased hiring or judicial systems, were not caused by single, easy-to-spot mistakes. They were the result of systemic patterns that manual checks could not find. A person looking at a few dozen or even a few hundred model responses cannot see the small statistical drifts spread across millions of data points.
It’s worth noting that AI models used in high-risk sectors like finance or medicine need built-in control mechanisms anyway, often called guardrails. These are automatic safety barriers that check the model’s responses in real time before they reach the end-user. They can block dangerous content or information that goes against company policy.
Since organisations already have to invest in developing these mechanisms for their live systems, it makes sense to use similar tools for automatic AI model testing.
Main risk areas in AI systems
The unpredictable nature of AI as a source of uncertainty
AI systems, unlike traditional software, do not always behave in the same way. This means the same question, or prompt, given to the model twice might produce two different, though often similar, answers. This key feature is the source of AI’s great potential, but it is also one of the biggest challenges for testing.
Even though model providers boast about high success rates in standard tests, their performance in real-world situations is often limited by a mix of technical and ethical problems. That’s why judging an AI system is about more than just saying if it “works” or “doesn’t work.”
Despite using modern techniques like fine-tuning and Retrieval-Augmented Generation (RAG), the average chance of at least one of 11 common errors happening in a single request for the GPT-4 model is as high as 62.46%. This means even well-set-up AI systems are at risk of things like hallucinations, biases, or being tricked by prompt injections.
The faithfulness crisis and the “black box” problem
Complex AI models are often compared to “black boxes.” We can see what goes in and what comes out, but the decision-making process inside the model is not clear to us. The field of Explainable AI (XAI) was born to tackle this.
It provides techniques and tools that let us get a better idea of how AI models “think.” However, in solving one problem, we have created another, perhaps even deeper one: a crisis of faithfulness. The problem is that an explanation from an XAI system is not always a true reflection of the model’s actual decision-making process.
In other words, the model might give a logical-sounding reason for its answer that has nothing to do with how the answer was actually produced. This becomes critical in regulated sectors like finance. Companies are required to prove to regulators why, for example, a loan application was rejected, and an unreliable explanation can lead to financial penalties.
It can also lead to teams making important business decisions based on false or misleading information. They might believe they understand how the model works when they are actually relying on an illusion. The scale of this issue is food for thought.
Research published in the Proceedings of Machine Learning Research shows that without proper setup, the consistency scores for popular XAI tools can be extremely low (even 0.0). Other analyses on the arXiv service indicate that over 62% of explanations from LLMs do not match the model’s decision.
Systemic bias and its legal and reputational consequences
The risk of bias is seen as one of the most socially harmful problems related to AI. AI models learn from the data we give them during training. If this data reflects existing societal prejudices – racial, gender, age-related, or other – the model will amplify them on a massive scale.
An AI system can unintentionally increase unequal treatment of different social groups. For example, a recruitment system might favour applications from men because fewer women have worked in that position in the past. Such actions expose the organisation to a triple risk: legal, reputational, and business-related.
This is not a theoretical problem. A report by the Congressional Black Caucus Foundation found that the COMPAS system was 77% more likely to negatively assess risk for black defendants. Research by the USC Viterbi School of Engineering showed that between 3.4% and 38.6% of so-called “facts” in AI knowledge bases show signs of bias.
New data privacy threats in the age of AI
Using massive amounts of data to train AI models has opened up completely new ways for attackers to threaten privacy. One of the best-known is a “membership inference” attack. This is where an attacker, through a series of cleverly designed questions, can work out with a high degree of probability whether a specific person’s data was used in the training set.
Even if the model does not directly reveal this data, the information that it was used is a serious breach of privacy. This risk has a very real financial and reputational cost. The global average cost of a data breach in 2024 was $4.88 million.
Also, as Termly reports, 57% of consumers are worried about their privacy in relation to AI. Given these threats, the only effective approach is a “privacy-by-design” philosophy. Data protection must be a built-in part of the system’s architecture from the very beginning.

Automated supervision as an answer to the challenges
The problems mentioned above lead us to one conclusion: the manual AI testing is a dead. Scaling up safely requires management and supervision systems that automate control processes.
What is Auditor?
Auditor is an integrated platform for AI Governance, which means it offers a complete way to manage AI. Its goal is to automate all the key processes involved in testing, continuous supervision, optimisation (training), reporting, and auditing of AI-based systems.
Auditor contains all the tools needed to make sure that an organisation’s AI systems are safe, reliable, ethical, and fully compliant with current regulations and internal quality policies. In short, instead of building from scratch and putting together dozens of separate tools, a company gets a ready-made, complete solution.
How does Auditor respond to the key risks?
- Answering costs and scalability: Auditor directly tackles the problem of manual, repetitive work. The platform automates a wide range of testing processes, including security tests, bias assessment, and checking the quality and performance of RAG mechanisms.
- Answering transparency and faithfulness: Unlike systems that act as “black boxes” themselves, Auditor was built on a foundation of transparency. The platform provides hard, measurable data on every aspect of the model’s performance, including the faithfulness of its explanations.
- Answering bias: Auditor approaches the problem of bias systematically. It supports one-off bias assessments and allows for the management of use case policies. A key and unique feature is the automatic generation of synthetic datasets for fine-tuning, creating a powerful feedback loop for continuous improvement.
- Answering data privacy: When it comes to data security, Auditor takes a no-compromise approach. The platform is designed to be installed directly within the client’s own infrastructure. This means no data ever goes “outside” to third-party providers.
Strategic benefits of automating AI supervision
Measurable financial savings as a direct return on investment
Using Auditor allows for specific, predictable savings that can be put directly into the budget. Estimates based on previous installations show cost reductions at the level of:
- -57% in the area of testing, auditing, and ongoing supervision of models.
- -81% in the area of creating reports for compliance and internal management.
Filling the “AI management gap”
According to the Artificial Intelligence News portal, only 5% of companies have mature, implemented frameworks for managing artificial intelligence. The rest are either reacting to problems as they happen or are just starting to create their own internal processes. Auditor offers a ready-made solution that allows companies to catch up and reach a level of maturity in a few months that would take others years to achieve.
Summary
Relying on manual AI testing is a dead end. It is too expensive, too slow, and unable to detect systemic risks like hidden biases or unbelievable explanations from models. In an age of mass AI adoption, this approach only creates huge costs and a dangerous illusion of control.
The solution is to automate supervision. Platforms like Auditor change AI management from reactive fire-fighting to a structured process based on hard data. For a company, this means a triple benefit: a drastic reduction in the cost of QA teams, critical risk management in the face of regulations like the AI Act, and—thanks to CI/CD integration—the ability to innovate much faster and more safely.
This blog post was created by our team of experts specialising in AI Governance, Web Development, Mobile Development, Technical Consultancy, and Digital Product Design. Our goal is to provide educational value and insights without marketing intent.


